We Are Launching Private Cloud on the VMware platform
We are expanding our portfolio of services with a fully managed private cloud on the VMware platform. You can now choose whether you prefer a private cloud built on the open-source Proxmox solution, or choose a licensed enterprise solution from the market leader in virtualization, VMware.
Moving applications to the cloud has a number of undeniable benefits, but its most popular form offered by global providers has a number of operational pitfalls: you give up the ability to customise your entire environment, allow a third party to have access to your data, and run the risk of vendor lock-in.
If you are one of the more demanding clients, you definitely need an exclusive cloud for your application, which is just for you and custom-made. You need a private cloud that, unlike a public cloud, fully adapts to the needs of your application.
The private cloud takes the benefits of the public cloud and grafts them onto a solution that you have full control over and where your freedom is not restricted in any way.
Example of Private cloud infrastructure
What a vshosting~ private cloud on the VMware platform looks like
We build each private cloud on the latest hardware from HP, DELL, Supermicro, Intel, and AMD. If you choose the VMware platform, we will use the vSphere tool for virtualisation, in the Standard or Enterprise version. Taking care of the overall design, its implementation as well as ensuring smooth operation in a high availability mode are a matter of course with vshosting~. All including professional advice from our administrators.
The cloud solutions we provide always include comprehensive server infrastructure management and exceptional 24/7 support with 60-second response times. The private cloud on VMware is no exception.
Our experienced administrators use advanced server management software, VMware vCenter (Standard version), which serves as a centralised platform for controlling the vSphere environment. Whether your applications run on Windows or Linux, we provide server management for you.
Are you considering a private cloud solution on VMware? Get in touch with our consultants: consultation@vshosting.co.uk and discuss the options and features of VMware. No strings attached.
Advantages of Kubernetes from vshosting compared to traditional cloud providers
What sets the Platform for Kubernetes service from vhosting~ apart from similar solutions by Amazon, Google or Microsoft? There is a surprising amount of differences.
What sets the Platform for Kubernetes service from vshosting~ apart from similar solutions by Amazon, Google or Microsoft? There is a surprising amount of differences.
Kubernetes services development
Clients often ask us how our new Platform for Kubernetes service differs from similar products by Amazon, Google or Microsoft, for example. There are in fact a great many differences so we decided to dig into the details in this article.
Individual infrastructure design
The majority of traditional cloud providers offer an infrastructure platform, but the design and individual creation of the infrastructure is left to the client – or rather to their developers. The overwhelming majority of developers will of course tell you that they’d rather deal with development than read a 196-page guide to using Amazon EKS. Furthermore, unlike most manuals, you really need to read this one since setting up Kubernetes on Amazon isn’t very intuitive at all.
At vshosting~ we know how frustrating this is for most companies. The development team should be able to concentrate on development and not waste time on something that they’re not specialised in. Therefore, we make sure that unlike traditional cloud services, our Kubernetes solution is tailor-made for each client. With us, you can skip the complex task of choosing from predefined packages, reading overly long manuals, and having to work out which type of infrastructure best meets your needs. We will design Kubernetes infrastructure exactly according to the needs of your application, including load balancing, networking, storage and other essentials.
In addition, we would love to help you analyse your application before switching to Kubernetes, if you don’t already use it. Based on your requirements we’ll recommend you a selection of the most suitable technologies (consultation is included in the price!), so that everything runs as it should and any subsequent scaling is as straightforward as possible.
In terms of scaling, with Zerops it’s simple. Again there is no choosing from performance packages etc. at vhosting~ you simply scale according to your current needs, no hassle. We also offer the option of fine scaling for only the required resources. Does your application need more RAM or disk space because of customer growth? No problem.
After we create a customised infrastructure design, we’ll carry out the individual installation and set up of Kubernetes and load balancers before putting it into live operation. Just for some perspective, with Google, Amazon or Microsoft, all of this would be on your shoulders. At vshosting~ we carefully fine-tine everything in consultation with you. Once launched, Kubernetes will run on our cloud or on the highest quality hardware in our own data centre, ServerPark.
The option of combining physical servers and the cloud
Another benefit of Kubernetes from vshosting~ is the option of combining physical servers with the cloud – other Kubernetes providers do not allow this at all. With this option you can start testing Kubernetes on a lower performance Virtual Machine and only then transfer the project into production by adding physical servers (all at runtime) with the possibility of maintaining the existing VMs for development.
For comparison: Google will for example offer you either the option of on-prem Google Kubernetes Engine or a cloud variant, but you have to choose one or the other. What’s more, you have to manage the on-prem variant “off your own back”. You won’t find the option of combining physical servers with the cloud with Amazon or Microsoft.
You save up to 50% compared to global Kubernetes providers. Take a look at how we compare.
Global Kubernetes providers
With us you can combine physical servers with the cloud as you see fit and we’ll also take care of administration – leaving you to focus on development. We’ll oversee the management of the operating systems for all Kubernetes nodes and load balancers and we’ll provide regular upgrades of operating systems, kernels etc. (and even an upgrade of Kubernetes, if agreed).
High level of SLA and senior support 24/7
One of the most important criteria in choosing a good Kubernetes platform is its availability. You might be surprised to learn that neither Microsoft AKS nor Google GEK provide a SLA (financially-backed service level agreement) and only claim to “strive to ensure at least 99.5% availability”.
Although Amazon talk about a 99.9% SLA, when you look at their credit return conditions, in reality it’s only a guarantee of 95% availability – since Amazon only return 100% of credit below this level of availability, If availability drops only slightly below 99.9%, they only return 10% of credit.
At vshosting~ we contractually guarantee 99.97% availability, that is to say more than Amazon’s somewhat theoretical SLA and significantly more than the 99.5% not guaranteed by Microsoft and Google. In reality, availability with vshosting~ is more like 99.99%. In addition., our Managed Kubernetes solution works in high-availability cluster mode which means that if one of the servers or part of the cloud malfunctions the whole solution immediately starts on a reserve server or on another part of the cloud.
We also guarantee high-speed connectivity and unlimited data flows to the whole world. In addition we ensure dedicated Internet bandwidth for every client. Our network has capacity up to 1 Tbps and each route is backed up many times over.
Thanks to the high-availability cluster regime, high network capability, and back up connection, the Kubernetes solution from vshosting~ is particularly resistant to outages of any part of the cluster. Furthermore, our experienced team will continuously monitor your solution and quickly identify any issues that emerge before they can have an effect on the end user. We also have robust AntiDDoS protection which effectively defends the entire cluster against cyber attacks.
Debugging and monitoring of the entire infrastructure
Unlike traditional cloud providers, at vshosting~ our team of senior administrators and technicians monitor your solution continuously 24 hours a day directly from our data centre and will react to any problems which may arise within 60 seconds – even on Saturday at 2am. These experts continuously monitor dozens of parameters relating to the entire solution (hardware, load balancers, Kubernetes) and as a result are able to prevent most issues before they become a problem. In addition, we guarantee to repair or replace a malfunctioning server within 60 minutes.
To keep things as simple as possible, we’ll provide you with just one service contact for all your services- whether it’s about Kubernetes itself, its administration or anything to do with infrastructure. We’ll take care of routine maintenance and complex debugging. Included in the Platform for Kubernetes price we also offer consultation regarding specific Dockerfile formats (3 hours a month).
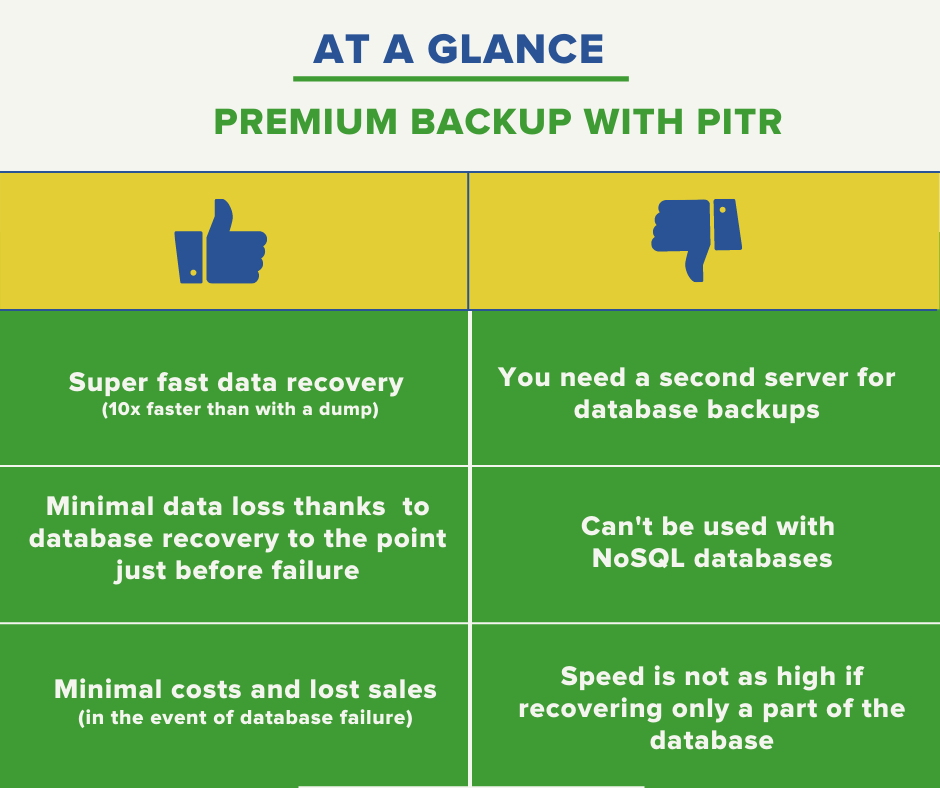
Premium Database Backup with Point-In-Time Recovery: MariaDB and PostgreSQL
Now is the time to get ready for the e-commerce season.
Imagine you’re in the middle of the peak season, marketing campaigns are in full swing and orders are pouring in. Sounds nice, doesn’t it? Unless the database suddenly stops working that is. Perhaps an inattentive colleague accidentally deletes it. Or maybe the disk array fails – it doesn’t matter in the end, the result is the same. Orders start falling into a black hole. You have no idea what someone bought and for how much, let alone where to send it to them. Of course, you have a database backup, but the file is quite large and it can take several hours to restore.
Now what?
Roll up your sleeves, start pulling the necessary information manually from email logs and other dark corners. And hope that nothing escapes you. But those few hours of recovery will be really long and incredibly expensive. Some orders will certainly be lost and you will be catching up with the hours of database downtime for a few more days.
Standard database backup (and why recovery takes so long)
Standard backup, which most larger e-shoppers are used to, is carried out using the so-called “dump” method, where the entire database is saved as a single file. The file contains sequences of commands that can be edited as needed. This method is very simple to implement. Another advantage is that the backup can be performed directly on the server on which the database is running.
However, a significant disadvantage of the dump is the time needed to restore the database from such a backup. This applies especially to large databases. As each command must be reloaded separately from the saved file into the database, the whole process can take several hours. At the same time, you can only restore the data that was contained in the last dump – you will lose the latest entries in the database that have not yet been backed up. The result is an unpleasant scenario described in the introduction – a lot of manual work and lost sales.
Premium backup with Point-in-time recovery
In order for our clients to avoid similar problems, we offer them premium database backups. This service allows for very fast recovery of databases, to the state just before the moment of failure. We achieve this by combining snapshot backups with binary log replication.
How does it work exactly?
We create an asynchronous replica from the primary database to the backup server. On this backup server, we make a backup using a snapshot. In parallel, we continuously copy binary logs to the backup server, which record all changes in the primary database. In the event of an accident, the logs will help us determine exactly when the problem occurred. At the same time, thanks to them, we have records of operations that immediately preceded the accident and are not backed up by a snapshot.
By combining these two methods, we can – in case of failure – quickly restore the database to its original state (so-called Point-in-time recovery, recovery to a point in time).
First, we restore the latest backup snapshot and copy it to the primary server from the backup server. Subsequently, for binary logs, we identify the place where the destructive operation took place and use them to restore the most recent data.
The speed of the whole process can be as much as 10 times higher than recovery from a dump. It is limited only by the write speed to the disk and the network connection. With a database of around 100 GB, the length of the entire process will be in the order of dozens of minutes.
What is needed for implementation?
Unlike the classic dump backup, which you can perform directly on the primary server, you need a backup server for the premium option. This server should have similar performance as the production server. The size of the storage is also important: we recommend about twice the volume of the disk with the primary database. This capacity should allow snapshots to be backed up for at least the last 48 hours (if you opt for hourly backups).
We will be happy to recommend the ideal storage volume for your database – book a free consultation at consultation@vshosting.co.uk.– it depends on the frequency of backups, the number of changes in your database, and other factors.
Premium backup also depends on the choice of database technologies. Due to the use of binary logs, it can only be implemented in relational databases such as MariaDB or PostgreSQL. NoSQL databases do not have a transaction log and are therefore not compatible with this method.
Another condition is a more conservative database setup on the backup server. The repository must always be consistent in order to take snapshots using ZFS. Upgrades that prioritise database performance over consistency cannot be used on the backup server. Therefore, it is necessary to choose a faster storage option than on the primary server, where a higher performance setting that reduces consistency is feasible.
Is the premium database backup for you?
If you can’t afford to lose any data in your business, let alone run for hours without a database, our premium backup with Point-in-time recovery is right for you. An example of a project that will benefit the most from this service is an online store with large databases, which would cost thousands of euros. In this case, an investment in the backup server needed for premium backup will pay off very quickly.
Conversely, if you have a smaller database with just a few changes per hour, you’re probably perfectly fine opting for a standard dump backup.
But your cargo will probably sink, and you will scramble to try and save as much of it as possible. To avoid this, we recommend that you prepare in advance for the expected fluctuations in infrastructure load. Among the most demanding e-commerce events are Christmas and Black Friday.
Online stores are traditionally preparing for Christmas in the summer. That’s when it’s time to think not only about marketing campaigns to attract as many customers as possible but also about the technical background that needs to withstand their influx to the website. The key is to know the average traffic to your site. And what the last season was like. Once you have this comparison, you can simply calculate roughly how much increase you can expect this year.
But what if you do even better than last year? That would be great but be prepared for this very desirable option. We recommend having an extra infrastructure capacity of approx. 20% on top of your estimate from the calculation above. However, it is always best to consult your hosting provider directly about tailor-made capacity reserves.
How to calculate the necessary capacity
For a simple calculation of infrastructure capacity, it is sufficient to compare the expected numbers with the current data. If you assume that the application will scale linearly, you can simply use last year’s high season increase in traffic compared to the average traffic in the first half of the year. Use that percentage increase combined with this year’s traffic and you’ll find out what system resources you’ll need this time around.
The advantages of this method are its speed and minimal cost. However, it is only a rough approximation. A more accurate alternative would be the so-called performance test. During this process, we simulate large traffic using an artificial load, while monitoring which components of the infrastructure become bottlenecks. This method also reveals configuration or technological limitations. However, it is fair to mention that performance tests are time-consuming as well as highly specific depending on the technologies used. For small and medium-sized online stores, they can therefore be unnecessarily expensive.
Pro tip: For example, the popular Redis database is single-threaded, so when the performance of a single core becomes saturated, it has reached its maximum at that point, and it doesn’t matter that the server has dozens of free cores available. Simply because such an application cannot use them.
Getting technical: 4 things to watch
CPU – beware of misleading CPU usage graphs if hyperthreading is enabled. The graph aggregating performance across all processor cores then greatly distorts the available performance. Although hyper thread theoretically doubles the number of cores, it practically doesn’t add twice the power. If you see values above 50% on such a graph, you are very close to the maximum… This is typically somewhere between 60 and 70%, depending on the type of load.
RAM – RAM usually does not grow linearly. For example, for databases, some memory allocations are global and others are separate for each connection. It often gets forgotten that the RAM cannot get completely full. If it does, all you need is a small allocation requirement, and the core kills the process that the memory required.
The operating system typically uses the memory reserve as a disk cache, which has a positive effect on performance. If caching is not sufficient, disk operation needs to increase.
Disks – Low disk speeds are a common reason that some operations are slow or completely inoperable at high loads. Whether the solution is sufficient will be shown only at high load or during a performance test. This load can be reduced by more intensive caching, which requires more RAM. It is also possible to solve the situation, for example, by upgrading from SATA / SAS SSD to NVMe disks.
It is also necessary to consider capacity because it can also affect overall performance. All filesystems using COW (copy-on-write) – for example, the ZFS we use, or file systems such as btrfs or WAFL – need extra capacity to run. All of these file systems share an unpleasant feature: when about 90% of the capacity becomes occupied, performance starts to degrade rapidly. It is important not to underestimate this – in times of heavy load, more data is often created and capacity is consumed faster.
Network layer – especially important for cluster solutions, where servers communicate a lot with each other and the speed for internal communication can easily become insufficient. It is also appropriate to consider redundancy – the vshosting~ standard is the doubling of the network layer with the help of LACP technology. So, for example, we make one 2GE interface from 2x 1GE. This creates a capacity of 2GE, but in practice, it is not appropriate to use up more than 1GE, because at that moment we are losing redundancy on the server.
Even the fact that the solution uses a 10GE interface does not mean that such a solution will suffice under all circumstances. All it takes is a small developer error when a simple query transfers a large amount of unnecessary data to the database (typically select * from… and then takes the first X lines in the application) and it is easy to deplete even such a large bandwidth.
For most of us, 2020 developed completely differently than we imagined at the time of our New Year’s toast. The pandemic turned everything upside down and much still remains that way. Not all the changes were for the worse, however, and many plans got implemented despite the virus. Here are vshosting~ milestones of last year.
Turnover plus 20%
Each year since our founding in 2006, we have been proud of our quick growth. But 2020 was really something. Already in the spring, the coronavirus switched digitalisation over to rocket fuel and everyone rushed to be online like never before. For us, it immediately meant another business peak comparable to Christmas, and since then the situation has calmed down only partially.
It was challenging, but we are pleased to say that we have helped dozens of clients move their business primarily to the world of the Internet. To another hundred or so businesses, we assisted with dramatically strengthen their existing e-shops. In numbers, this represents a year-on-year increase in turnover of as much as 20%.
Data centre capacity grew by 2,500 servers
Thanks to the rapid influx of new clients (thank you!), our ServerPark data center has begun to burst at the seams. That is why we started to build the last stage of the data centre, which we successfully completed last fall.
We used our technological reserves to the maximum and installed large 52U racks. This means increased capacity of the data centre by about 2,500 servers! To keep up with such a boost, we also added 2 new transformer stations (800kVA and 630kVA) and increased the cooling capacity by adding 4 condensers to the roof and 2 new air conditioning units (each with an output of 100kW).
Connectivity increased to 2 x 100 Gbps
We also keep up with the growing data flows of our clients. Newly, vshosting~ has a fully redundant capacity of 2 x 100 Gbps to the NIX.CZ node. That’s five times more than the original 2 x 20 Gbps! We also upgraded the network technologies connecting our ServerPark data centre with the TTC DC1 data centre (this is used for backups in a geographically separated location and for the implementation of connections with other operators).
The new technology has a transmission speed of 2 x 100 Gbps and connects both data centres via two independent optical routes. All data transfers, including backups, are even faster and more secure than before.
German investor patronage
2020 marked a huge milestone for us because vshosting~ has become part of the German investment group Contabo. Contabo has hosting businesses growing across Europe as well as within the USA, and thanks to their support, we can grow at an even faster pace than before.
In addition to hosting, our new investors are also helping us kick off the long-awaited Zerops project, which we launched in a private version in August last year.
What will 2021 bring?
We will not be idle this year either as we are preparing a lot of news for you. First of all, the public version of Zerops won’t be long in coming – we plan to launch it in April 2021. You can look forward to a fully functional, automated platform for developers that will make their coding dramatically easier.
Another novelty will be the launch of an AWS-based solution. We thus cater to our clients who have shown interest in this opportunity, and we offer a more advantageous alternative for those who do not want to give up AWS completely.
Last but not least, we will dive into our long-awaited expansion to the Hungarian market, where we want to offer reliable hosting services for e-commerce projects.
5 Years of Running a Data Centre: Business Lessons Learned
What we’ve learned from 5 years of operating our own data center and what we’re still working on.
In August 2015, we officially opened our own ServerPark data centre in Hostivař, Prague. As a hosting service provider, vshosting~ had already been operating for 9 years at that time. However, with the launch of ServerPark, a new era began. The most important business lessons we have learned in the 5 years that followed could be summarised thusly: paranoia = the key to success, there’s no such thing as “can’t”, and herding cats.
Paranoia = the key to success
As hosting providers, we have paranoia in the job description already. If you also run a data centre, this is doubly true. Maximum security and ultra-high availability of services are of the utmost importance for our clients. For this reason, we have implemented even stricter measures in our data centre compared to the industry standard. We have doubled all the infrastructure and even added an extra reserve for each element in the data centre.
In contrast, in most other data centres, they only choose the duplication of infrastructure or even only one reserve. It’s much cheaper and the chances of, say, more than half of your air conditioning units failing are minimal, right?
You know what they say: just because we’re paranoid doesn’t mean they’re not after us. Or that three air conditioning units cannot break at the same time. Therefore, we were not satisfied with this standard and we can say that it has paid off several times in those 5 years. Speaking of air conditioning: for example, we once performed an inspection of individual devices (for which, of course, it is necessary to turn them off) and suddenly a compressor got stuck in one of the spare air conditioning units. It would be a disaster for a standard data centre, but it didn’t even faze us. Well, we just had to order the compressor…
Unlike most other data centres, even after 5 years, we can boast of completely uninterrupted operation. Extra care pays off, and this is doubly true for a data centre.
We also rely on large stocks of hardware. So large that many other hosting providers would find them unnecessary. However, we have once again confirmed that if we want to provide clients with excellent service in all circumstances, “supply paranoia” pays off.
A great example was the beginning of this year’s coronavirus crisis. Due to the increased interest in online shopping, many e-shops needed to significantly increase capacity – even double it in some cases. At the same time, the pandemic around the world has essentially halted the flow of hardware supplies. If we had to order the necessary servers, the client’s infrastructure would simply collapse under the onslaught of customers before the hardware would arrive. But we simply pulled the servers out of the warehouse and installed them almost immediately.
There’s no such thing as “can’t”
Another lesson we learned from running a data centre is the need to think out of the box. As hosting service providers and data centre operators, we must fulfill the client’s ideas about their server infrastructure from start to finish. Having the “we can’t do that” attitude is simply not an option in this business. You either come up with a solution or you’re done for in this industry.
In 5 years of operating the data centre, we have faced our fair share of challenges. Whether it’s designing a giant infrastructure for the biggest local e-commerce players or transforming an entire hosting solution into a brand new technology unknown to us, we’ve learned to never give up before the fight. The results are usually completely new, unique solutions, courtesy of our amazing admins. It is said that the work of an administrator is typically quite stereotypical. Well, not in our company. We have more than enough challenges for each and every one of them.
Of course, there are also requirements that simply cannot be met. The laws of physics are, after all, still in place. Also, sometimes the price of a solution is completely outside the business reality. Even in such cases, however, we have come to the conclusion that it is always worthwhile to look for alternative solutions. Of course, they will not be completely according to the original assignments, but you can come pretty close.
Summing up: we always look for ways to honor our client’s wishes, not for reasons why we cannot.
Herding cats aka how to manage a company with teams all over Prague
When we were building the data centre, there were about 20 of us in the company. Above the data hall, we added a floor with offices and facilities with then seemingly unreasonably large capacity of 50 people. We figured that it would take us a good number of years to grow so much. In the end, it took only three.
Today there are about eighty of us (plus 5 dogs, 1 lizard, and 1 hedgehog working part-time). We’ve had zero chance of fitting into the data centre for quite some time, so we’ve undertaken slight decentralisation. The developers are based in Holešovice and sales and marketing reside in Karlín. From the point of view of company management and HR, such a fragmentation of the company presents a great challenge.
What were the lessons learned? Primarily, that effective communication is really hard but totally worth it. After all, many growing companies run into some type of communication trouble: once there’s more than 25 of you, it is no longer enough to naturally pass on information while waiting for the coffee to brew. When you combine this growth with a division of teams to different locations, the effect multiplies.
We have learned (and in fact are still learning) to share information between teams more regularly and in a more structured way to avoid misunderstandings. Because misunderstandings give rise to unnecessary conflicts, inefficient work, and general frustration. On the other hand, we are no fans of endless meetings with everyone. So what’s the best way to go about it?
For example, we regularly send everyone an in-house newsletter, to which each team in the company contributes updates about what they are doing, what new things they are preparing, and what has been particularly successful. Thanks to this, even a new salesman knows what technicians are doing for the success of our company, and admins understand why marketing wants them to check articles. We break our team stereotypes and constantly remind ourselves that we all pull together.
Our wonderful HR also makes sure that they show up in all our offices every week. That way they have a very good idea of the atmosphere everywhere in the company and the preferences of specific teams. A pleasant side effect are the spontaneous post-work tastings of alcoholic beverages, throughout which, as is well known, relationships are strengthened the most.
After 5 years of operating a data center and 14 running the whole company, we are by no means experts. However, we keep going forward, never stop working on ourselves, and most importantly: we still love it.
How We Upgraded GymBeam’s Infrastructure to the Ultra-Powerful EPYC Servers
How and why we improved GymBeam’s infrastructure, what’s so great about EPYC servers, and who will benefit most from this amazing hardware.
We made major upgrades to the infrastructure of one of the biggest e-commerce projects in the Czech Republic and Slovakia: GymBeam. And they’re not just some minor improvements – we exchanged all the hardware in the application part of their cluster and installed the extra powerful servers (8 of those bad boys in total).
How did the installation go, what does it mean for GymBeam, which advantages do EPYC servers provide, and should you be thinking of this upgrade yourself? You’ll find out all that and more in this article.
What’s so epic about EPYC servers?
Until recently, we’ve been focusing on Intel Xeon processors at vshosting~. These have been dominating (not only) the server product market for many years. In the last couple of years, however, the significant improvement in portfolio and manufacturing technologies of the AMD (Advanced Micro Devices) company caught our attention.
This company newly offers processors that offer a better price/performance ratio, a higher number of cores per CPU, and better energy management (among other things thanks to a different manufacturing technology – AMD Zen 2 7nm vs. Intel Xeon Scalable 14nm). These processors are installed in the AMD EPYC servers we have used for the new GymBeam infrastructure.
They are the most modern servers with record-breaking processors with up to 68 cores and 128 threads (!!!). Compared to the standard Intel Xeon Scalable, where we offer processors with a maximum of 28 cores per CPU, the volume of computing cores is more than double.
The EPYC server processors are manufactured using the 7 nm process and the multiple-chipsets-per-case method, which allows for all 64 cores to be packed into a single CPU and ensure a truly noteworthy performance.
How did the installation go
The installation of the first servers based on this new platform went flawlessly. Our first step was a careful selection of components and platform unification for all of the future installations. The most important part at the very beginning was choosing the best possible architecture of the platform together with our suppliers and specialists. This included choosing the best chassis, server board, peripherals including the more powerful 20k RPM ventilators for sufficient cooling, etc. We will apply this setup going forward on all future AMD EPYC installations. We were determined for the new platform to reflect the high standard of our other realisations – no room for compromise.
As a result, the AMD EPYC servers joined our “fleet” without a hitch. The servers are based on the chassis and motherboards from the manufacturer SuperMicro and we can offer both 1Gbps and 10Gbps connection and connection of hard disks both on-board and with the help of a physical RAID controller according to the customer’s preferences. We continue to apply hard drives from our offer, namely the SATA3 // SAS2 or PCI-e NVMe. Read more about the differences between SATA and NVMe disks.
Because this is a new platform for use, we have of course stocked our warehouse with SPARE equipment and are ready to use it immediately should there be any issue in production.
Advantages of the hardware for GymBeam’s business
The difference compared to the previous processors from Intel is huge: besides the larger number of cores, even the computing power per core is higher. Another performance increase is caused by turning on the Hyperthreading technology. We turn this off in case of the Intel processors due to security reasons but in case of the AMD EPYC processors, there’s no reason to do so (as of yet anyway).
The result of the overall increase in performance is, firstly, a significant acceleration in web loading due to higher performance per core. This is especially welcomed by GymBeam customers, for whom shopping in the online store has now become even more pleasant. Speeding up the web will also improve SEO and raise search engine “karma” overall.
In addition to faster loading, GymBeam gained a large performance reserve for its marketing campaigns. The new infrastructure can handle even a several-fold increase in traffic in the case of intensive advertising.
Last but not least, at GymBeam they can now be sure they are running on the best hardware available 🙂
Would you benefit from upgrading to the EPYC servers?
Did the mega-powerful EPYC processors catch your interest and you are now considering whether they would pay off in your case? When it comes to optimising your price/performance ratio, the number one question is how powerful an infrastructure your project needs.
It makes sense to consider AMD EPYC processors in a situation where your existing processors are running out of breath and upgrading to a higher Intel Xeon line would not make economic sense. That limit is currently at about 2x 14core – 2x 16core. Intel’s price above this performance is disproportionately high at the moment.
Of course, the reason for the upgrade does not have to be purely technical or economic – the feeling that you run services on the fastest and best the market has to offer, of course, also has its value.
Is Your SEO Being Sabotaged By Subpar Hosting?
How hosting quality affects SEO: 3 main factors. And what to do so that bad hosting does not push you off the top of the search results.
As the popular SEO joke goes, when you need to hide something really well, you put it on the second page of Google search results. That you can very easily end up in even better-concealed places due to your hosting provider is not quite as well known, though.
The search algorithms of Google and other search engines are strictly confidential. However, many of the factors that can kick you out of the coveted first page have been well documented by SEO experts. Typically they are low-quality texts on the website, content copied from elsewhere, or unseemly SEO practices.
The effect of hosting quality is often neglected. But it influences your SEO quite a bit and from three main angles: speed, outages, and location.
1) Website speed
The faster your website loads, the better your search engine ranking becomes. Of course, top-notch website speed alone will not ensure the first spot in the results for you. On the other hand, there’s no way you’ll make it to the top without it. Combined with other SEO strategies, speeding up your site will help you climb the Google result ladder.
Why is that? Website speed isn’t just some abstract Google metric. Slow loading is the leading cause of website visitor’s leaving. That leads to worsening metrics such as bounce rate and time spent on the site which in turn causes bad “search engine karma” and pushes you further down in the search results.
In our experience, 3 seconds are a good benchmark. If it takes your site longer to load, your hosting might be at fault. Find out from your provider whether it’s caused by low performance, sharing resources with other users, or due to a suboptimal location of servers that store your data (we’ll get back to the location issue in a second).
Tip: Not sure how fast your website is? We recommend the PageSpeed Insights tool from Google. It gives you the option to measure the speed of both the desktop and mobile versions of your website.
2) Outages
Hosting outages are an unpleasant affair from start to finish – starting with unrealised sales, followed by loss of customer trust, and topped off with damaged SEO. That’s why we recommend you avoid them altogether by choosing a reliable hosting provider.
Wait a second – what do outages have to do with SEO? Unfortunately, quite a bit. For example, Google penalises websites that have been down for a while. Thus you’re risking a drop in your search result position. Getting back up is no easy task so prevention is key.
3) Location
The location in which the servers storing your data are placed is closely related to the speed of your website and therefore also SEO. It is primarily about how great the distance is between the servers and the visitor to your site. The longer the distance your data has to travel, the longer it takes for it to reach the user. If the distance is, say, 500 kilometers and your hosting provider uses quality operators, everything works great.
However, if you have servers in ServerPark in Prague and a visitor to your site is sitting at a Starbucks in Los Angeles, they may be unpleasantly surprised by the slow loading. The ideal solution in this case is the so-called CDN, which periodically caches the content of your website (i.e. stores it in locations that are closer to site visitors). The result is a significant acceleration of your site loading time and thus an improved position in search results.
When choosing a CDN, focus on where the provider has the so-called pops. That is for which locations it is able to ensure the fast delivery of your content. For example, vshosting~ has pops all over Europe and North America.
Top SEO is not just about keywords and interesting content. You also need the support of a quality hosting partner to reach the top of the search. Make sure your SEO efforts are not sabotaged by poor hosting quality.
Not All Backup Solutions Are Made Equal: 5 Key Questions to Ask Your Hosting Provider
Want to be able to rely on your backed up data? Here are the top 5 things to consider (and discuss with your hosting provider).
We all know that backups are important. But what next? Is it enough to simply “have a backup” and be done with it? You can probably tell already that it won’t be that simple. Here top 5 questions everyone should think about as well as discuss with their hosting provider.
1. How fast would the data recovery be?
An often overlooked but the essential question is the speed of data recovery from your backup solution. If you don’t pay attention to this, you can very easily end up in a situation where the renewal of your project takes 3 days (versus your expectations of 1 hour max). If you are a busy online store, for instance, 3 days offline constitutes a catastrophe.
The speed of recovery depends primarily on the amount of data you’re renewing and on the technology used. The data volume is given by the nature and size of your project – if you run an online business with a huge customer database, you’ll hardly be able to shrink it. However, even if there’s a lot of data to contend with, you can look for a solution that would allow for faster recovery (e.g. snapshot technology is much faster than rsync). Therefore, ask your provider how long data recovery would take in your case and if there are any options to speed it up.
2. Which backup frequency is best for me?
Another crucial aspect of backups is their frequency. For example, at vshosting~, we include a standard backup package with each managed service that backs up all the data once a day. But if you decide that’s not good enough for you, we can easily provide more frequent backups – say, once every hour (if your production configuration allows for it).
Of course, the more frequent the backups the more expensive your solution becomes because you need more storage space and infrastructure capacity. Especially if you want to keep all backup versions for 30 days or even longer. So, food for thought – how often do you need to back things up and how many versions do you need to keep stored?
3. What if the backup fails or gets delayed?
With projects that require backing up a huge volume of data, there’s a risk of the backup not completing within the given time frame. For instance, if you run backups once a day, the backup process needs to finish in 24 hours. If it doesn’t, a delay can occur or the backup can fail entirely.
At vshosting~, we prevent this from happening by using the ZFS filesystem as the default filesystem for all of our managed services. This filesystem natively supports backups via snapshots, just like the ones you know from virtual server backups. The snapshots ensure that the entire server is backed up as a single file. As a result, the process is super fast – almost immediate in fact. Even data recovery becomes vastly sped up thanks to snapshot technology (compared to rsync for example).
4. Where is my data stored?
From a security point of view, it is absolutely crucial that the backup is stored in a completely different location than the primary data. Ideally in another data center at the opposite end of town. In the event of a disaster at the location of your primary data, the backups will not be compromised.
It’s actually similar to backing up your computer to an external drive at home. After completing the backup, it is ideal to take the drive to your mother-in-law, for example, in case your apartment catches fire or something.
5. How are the backed up data secured?
Apart from backing your data up to a separate location, it is essential from a security point of view how easily an unauthorised person can access your data. The main defense against this is data encryption and limited access to data. At vshosting~, encryption is a standard measure and the backups of our clients can only be accessed from our internal network. However, you cannot rely on such a standard with all providers.
Don’t settle for having “some backup” from your hosting provider. Be demanding and ask for specifics. Your project deserves the best care.
9 Reasons to Give into the DevOps and Containerization Trends
DevOps and containerization aren’t just empty buzzwords. They can help you make development more efficient and customers happier. Here’s how.
DevOps and containerisation are among the most popular IT buzzwords these days. Not without reason. A combination of these two approaches happens to be one of the main reasons why developer work keeps getting more efficient. In this article, we’ll focus on 9 main reasons why even your project could benefit from DevOps and containers.
A couple of introductory remarks
DevOps is a composition of two words: Development and Operations. It’s pretty much a software development approach that emphasizes the cooperation of developers with IT specialists taking care of running the applications. This leads to many advantages, the most important of which we will discuss shortly.
Containerization fits into DevOps perfectly. We can see it as a supportive instrument of the DevOps approach. Similar to physical containers that standardised the transportation of goods, software containers represent a standard “transportation” unit of software. Thanks to that, IT experts can implement them across environments with hardly any adjustments (just like you can easily transfer a physical container from a ship to a train or a truck).
Top 9 DevOps and container advantages
1) Team synergies
With the DevOps approach, developers and administrators collaborate closely and all of them participate in all parts of the development process. These two worlds have traditionally been separated but their de facto merging brings forth many advantages.
Close cooperation leads to increased effectiveness of the entire process of development and administration and thus to its acceleration. Another aspect is that the cooperation of colleagues from two different areas often results in various innovative, out of the box solutions that would otherwise remain undiscovered.
2) Transparent communication
A common issue not only in IT companies is quality communication (or rather lack thereof). Everybody is swamped with work and focuses solely on his or her tasks. However, this can easily result in miscommunication and incorrect assumptions and by extension into conflicts and unnecessary workload.
Establishing transparent and regular communication between developers and administrators is a big part of DevOps. Because of this, everyone feels more like a part of the same team. Both groups are also included in all phases of application development.
3) Fewer bugs and other misfortunes
Another great DevOps principle is the frequent releasing of smaller parts of applications (instead of fewer releases of large bits). That way, the risk of faulty code affecting the entire application is pretty much eliminated. In other words: if something does go wrong, at least it doesn’t break the app as a whole. Together with a focus on thorough testing, this approach leads to a much lower number of bugs and other issues.
If you decide to combine containers with DevOps, you can benefit from their standardisation. Standardisation, among other things, ensures that the development, testing, and production environments (i.e. where the app runs) are defined identically. This dramatically reduces the occurrence of bugs that didn’t show up during development and testing and only present themselves when released into production.
4) Easier bug hunting (and fixing)
Eventual bug fixes and ensuring smooth operation of the app is also made possible by the methodical storage of all code version that’s typical for DevOps. As a result, it becomes very easy to identify any problem that might arise when releasing a new app version.
If an error does occur, you can simply switch the app back to its previous version – it takes a few minutes at the most. The developers can then take their time finding and fixing the bug while the user is none the wiser. Not to mention the bug hunting is so much easier because of the frequent releases of small bits of code.
5) Hassle-free scalability and automation
Container technology makes scaling easy too and allows the DevOps team to automate certain tasks. For example, the creation and deployment of containers can be automated via API which saves precious development time (and cost).
When it comes to scalability, you can run the application in any number of container instances according to your immediate need. The number of containers can be increased (e.g. during the Christmas season) or decreased almost immediately. You’ll thus be able to save a significant amount of infrastructure costs in the periods when the demand for your products is not as high. At the same time, if the demand suddenly shoots up – say that you’re an online pharmacy during a pandemic – you can increase capacity in a flash.
6) Detailed monitoring of business metrics
DevOps and containerization go hand in hand with detailed monitoring, which helps you quickly identify any issues. Monitoring, however, is also key for measuring business indicators. Those allow you to evaluate whether the recently released update helps achieve your goals or not.
For example: imagine that you’ve decided to redesign the homepage of your online store with the objective of increasing the number of orders by 10 %. Thanks to detailed monitoring, you can see whether you’re hitting the 10 % goal or not shortly after the homepage release. On the other hand, if you made 5 changes in the online store all at once, the evaluation of their individual impact would be much more difficult. Say that the collective result of the 5 changes would be the increase of order number by 7 %. Which of the new features contributed the most to the increase? And don’t some of them cause the order number to go down? Who knows.
7) Faster and more agile development
All of the above results in significant acceleration of the entire development process – from writing the code to its successful release. The increase in speed can reach 60 % or even more (!).
How much efficiency DevOps will provide (and how much savings and extra revenue) depends on many factors. The most important ones are your development team size and the degree of supportive tool use – e.g. containers, process automation, and the choice of flexible infrastructure. Simply put, the bigger your team and the more you utilise automation and infrastructure flexibility, the more efficient the entire process will become.
8) Decreased development costs
It is hardly a surprise that faster development, better communication and cooperation preventing unnecessary work, and fewer bugs lead to lowering development costs. Especially in companies with large IT departments, the savings can reach dozens of percent (!).
Oftentimes the synergies and higher efficiency show that you don’t need to have, say, 20 IT specialists in the team. Perhaps just 17 or so will suffice. That’s one heck of a saving right there as well.
9) Happier customers
Speeding up development also makes your customers happy. Your business is able to more flexibly react to their requests and e.g. promptly add that new feature to your online store that your customers have been asking for. Thanks to the previously mentioned detailed monitoring, you can easily see which of the changes are welcomed by your users and which you should rather throw out of the window. This way, you’ll be able to better differentiate yourself from the competition and build up a tribe of fans that will rarely go get their stuff anywhere else.
Key takeaways
To sum it all up, from a developer’s point of view, DevOps together with containers simplify and speed up work, improve communication with administrators, and drastically reduce the occurrence of bugs. Business-wise this translates to radical cost reductions and more satisfied customers (and thus increased revenues). The resulting equation “increased revenues + decreased costs = increased profitability” requires no further commentary.
In order for everything to run as it should, you’ll also need a great infrastructure provider – typically some form of a Kubernetes platform. For most of us, what first comes to mind are the traditional clouds of American companies. Unfortunately, according to our clients’ experience, the user (un)friendliness of these providers won’t make things easier for you. Another option is a provider that will get the Kubernetes platform ready for you, give you much needed advice as well as nonstop phone support. And for a lower price. Not to toot our own horn but these are exactly the criteria that our Kubernetes platform fits perfectly.
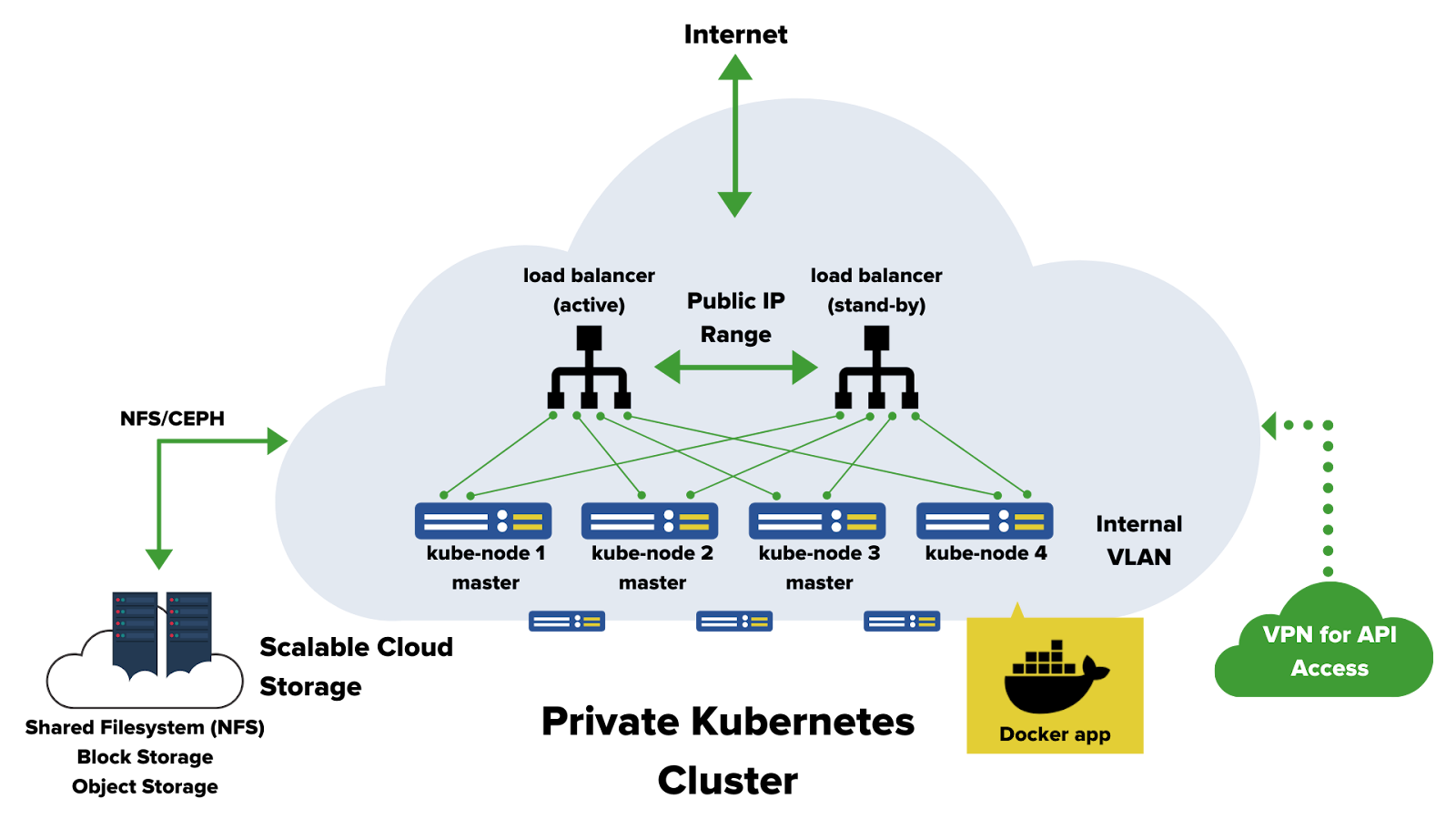
Example of infrastructure utilising container technology – vshosting~